

Último Leanalytics.
Pero solo hasta septiembre. Me tomaré un descanso en verano para recargas pilas. Sin embargo, quiero dejarte por aquí una lectura relajada sobre un tema que me absorbió desde la primera vez que oí hablar de él: el análisis causal.
Con esta edición doy el pistoletazo de salida a una nueva serie de contenido dedicada a este fantástico tema. Me lo voy a tomar con calma. Lo voy a disfrutar como un buen whisky y no descarto crear entre medio otros contenidos o incluso otras series (sí, sé que tengo algunos pendientes).
Sin más dilación, empieza la 20ª edición de Leanalytics.
Introducción a Análisis Causal + Calculadora Diff-in-Diff (Parte 1)
1. Mis primeras vivencias
Oí hablar por primera vez de análisis causal en 2023 cuando Alberto Labarga me dejó caer esta palabra clave en una tarde fría de enero y me dijo “esto empieza a estar de moda en el campo de la ciencia de datos”. Me llamó poderosamente la atención la palabra causal porque siempre ha sido el sueño húmedo de todos los que nos dedicamos al marketing: establecer causa y efecto de nuestras acciones.
Desde ese día, todo lo que han publicado hasta hoy editoriales como O’Reilly, Packt, Manning, Penguin Random House o incluso algunas traducciones a castellano que ha traído Anaya a nuestro país han acabado en mi estantería y (casi) todos han acabado leídos.
Esos libros desbloquearon en mí un universo nuevo. Una nueva manera de pensar y de entender el análisis de iniciativas de marketing desde una perspectiva que aúna técnica de alto nivel con una mirada cualitativa de las cosas. Esto me ha permitido (hasta la fecha):
En 2024, introducir en el área de CRO & Insights de LIN3S un protocolo de análisis con CausalImpact que nos permite identificar causa-efecto en aquellas variantes ganadoras lanzadas al 100% de los usuarios mediante un análisis se serie temporal. Si has trabajado con nosotros en el último año y medio estarás cansado de escuchar la palabra “ITSA”.
Hablando de esto: en la edición sobre análisis ITSA de productos digitales profundizo en técnicas asociadas a establecer un cierto grado de causalidad aplicada a negocio digital y explico cómo reportar y las ventajas que tiene este método con respecto a otros más típicos.
En Experimentación Online, en el último capítulo sobre tendencias futuras, apunto a que el análisis causal será norma en el futuro del negocio digital y recomiendo algunos libros y personas a seguir para estar al día.
1.1 ¿Qué relación guarda el Test AB con la causalidad?
Hace 3 meses tuve la oportunidad de asistir a un programa organizado por Economic AI en el que enseñaban análisis causal con una librería llamada DoubleML creada por ellos mismos. Sobre esta librería he construido la calculadora de diferencia en diferencias que encontrarás más abajo.
Allí vi que se repetía algo que me agradó y que he encontrado como “opinión más común” en libros, ponencias y formaciones de este tipo: “El Test AB (o RCT según el ámbito) es el Gold Standard de la Causalidad.” Como mucho, quizás superado por técnicas de meta-análisis como la combinación de p-valor que expliqué en este webinar y que popularizó a principios del 2024 Ron Kohavi para negocio online (aunque antes ya había escrito sobre ello en su libro).
El mismo Kohavi hace suya una frase de Winston Churchill para referirse al Test AB: “Many forms of Government have been tried, and will be tried in this world of sin and woe. No one pretends that democracy is perfect or all-wise. Indeed, it has been said that democracy is the worst form of Government except for all those other forms that have been tried from time to time.”
Es decir, te podrá gustar más o menos el test AB, pero sigue siendo el mejor método y el más fiable para establecer causa-efecto acerca de una acción de marketing, un medicamento o un estudio sociológico. Otra cosa es que analices mal y tengas juicios/prejuicios sobre esta técnica de análisis.
Pero… ¿Qué hacemos cuando es imposible hacer un test AB?
Aquí entra el análisis causal.
2. ¿Por qué Análisis Causal?
Un ejemplo memorable que explica muy bien por qué necesitamos análisis causal es este que explicaron en la formación de Economic AI: un modelo de Machine Learning (como una regresión o un modelo de clasificación) podría determinar que llevar un mechero en el bolsillo provoca cáncer de pulmón (y lo mejor: el modelo sería satisfactorio técnicamente hablando).
Esta afirmación, por pura lógica, es ridícula. Sin embargo abre la puerta a una idea incómoda para algunos: los modelos de ML tienden a trabajar con asociaciones mediante el aprendizaje de patrones complejos en los datos, mientras que la inferencia causal aprende de relaciones causales y va más allá de las puras “correlaciones” (Nota: a aquellos puristas de ML, dadle cierta distancia emocional al uso de la palabra “correlación” en este contexto).
Para bajarlo a tierra, veámoslo con un ejemplo:
Desde una perspectiva de modelado predictivo que busca predecir el churn rate, nos preguntaríamos: ¿cómo podemos construir una serie de reglas que predigan Y (el churn) utilizando las features X (una serie de variables)? Así, surgirían nuevas preguntas específicas que ML puede responder:
¿Cuán bien podemos predecir a los usuarios que se irán?
¿Qué variables explican mejor el churn?
Pero desde una perspectiva causal las preguntas serían diferentes: ¿cómo influye causalmente la acción D (una iniciativa, tratamiento o intervención) sobre el resultado Y (una métrica o efecto determinado, por ejemplo)? Así, surgirían nuevas preguntas que específicamente el análisis causal puede responder:
¿Por qué los usuarios se van?
¿Cómo podemos retener más usuarios?
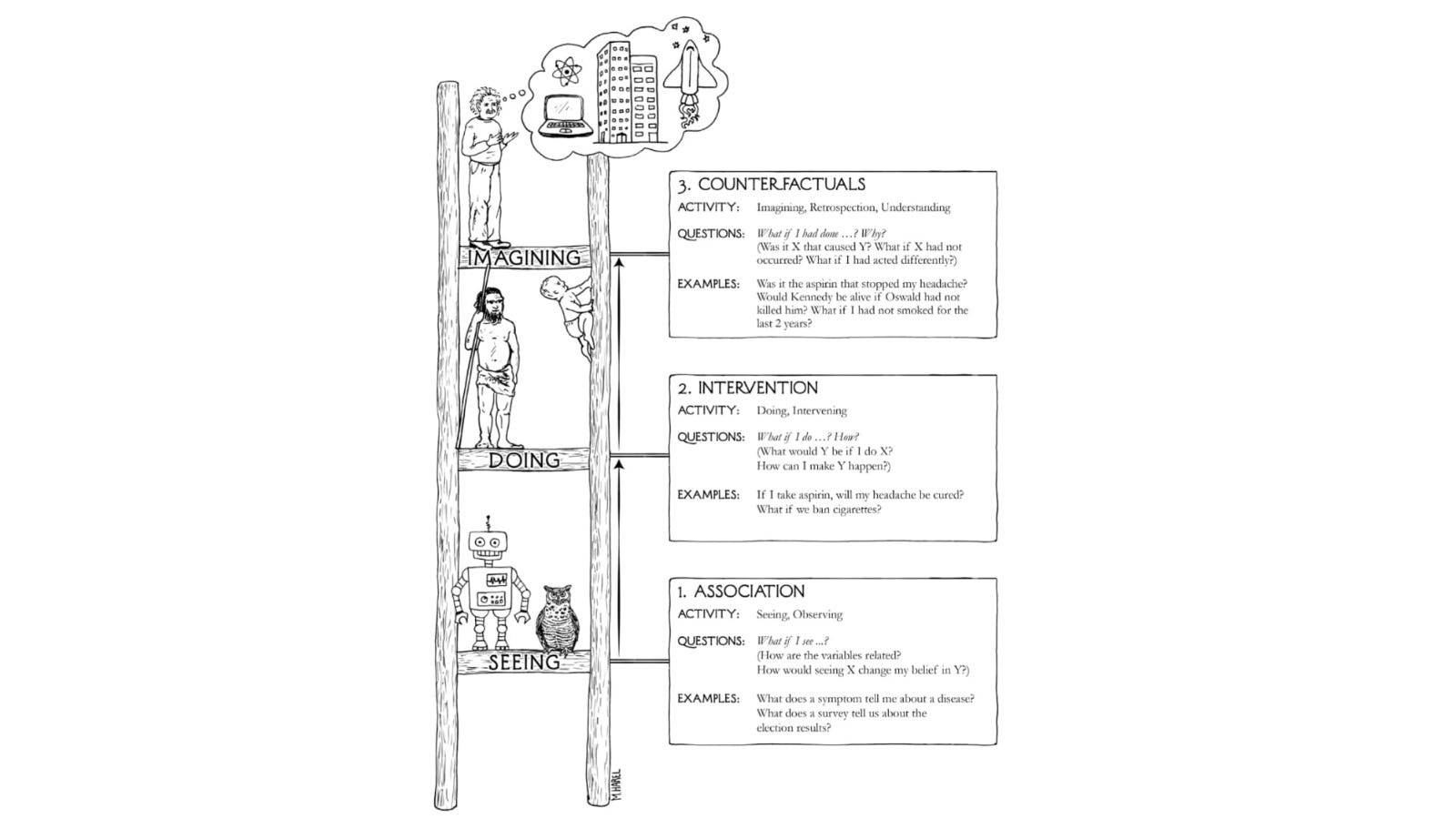
Esta imagen del libro “The Book of Why” de Judea Pearl (uno de los padres de la causalidad) es demoledora y creo que envejecerá francamente bien. Fíjate que “las máquinas” están debajo de todo en el campo de “la asociación” mientras que un poco más arriba reside el ser neandertal que interactúa con el mundo (intervention) y desde ahí lo comprende.
Finalmente, en lo más alto el ser humano actual que imagina cosas que realmente no han pasado y aplica “contrafactuales” (de esto ya hablamos parcialmente en esta edición, pero profundizaremos más en siguientes ediciones).
El análisis causal permite dar respuesta técnica a una cuestión que genera quebraderos de cabeza a los científicos de datos: la explainability. Es decir, a explicar por qué suceden los fenómenos que nos rodean de manera empírica. Esta es la razón de ser del análisis causal y el motivo por el que me interesó tanto es porque CRO hunde sus raíces en la causalidad: en entender cómo los usuarios se comportan y qué output generan estos a partir de un estímulo nuevo que hemos construido (nuestra variante).
3. Vocabulario y conceptos clave
3.1 DAGs
Conocidos en inglés como Directed Acylic Graphs (DAGs) nos permiten comunicar, detectar relaciones e identificar los problemas relacionados para establecer causalidad alrededor de una pregunta de investigación general o específica.
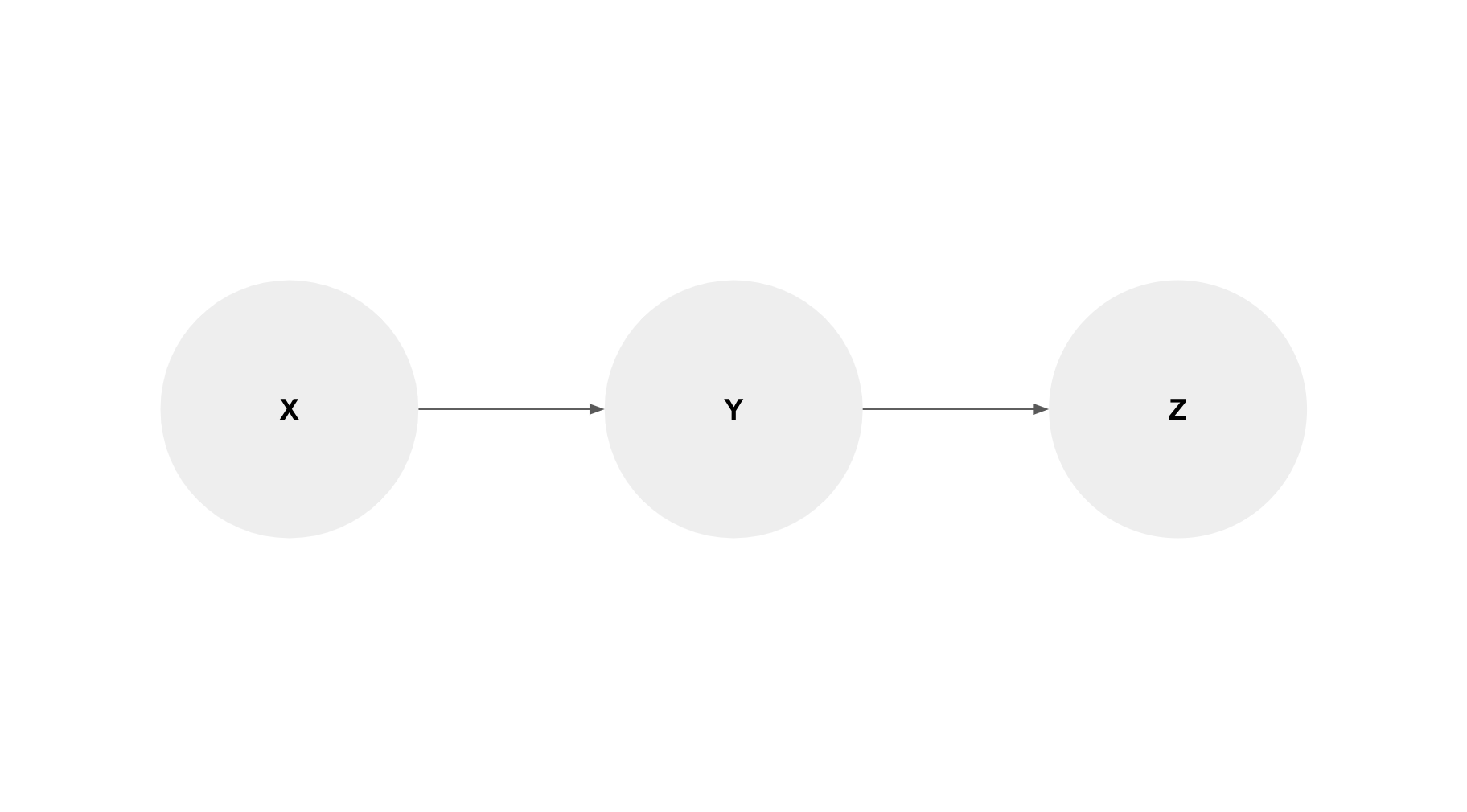
3.1.1 Mediators
“X afecta a Z causalmente a través de Y”. Esto significa que condicionar en Y o bloquearlo puede afectar a Z.
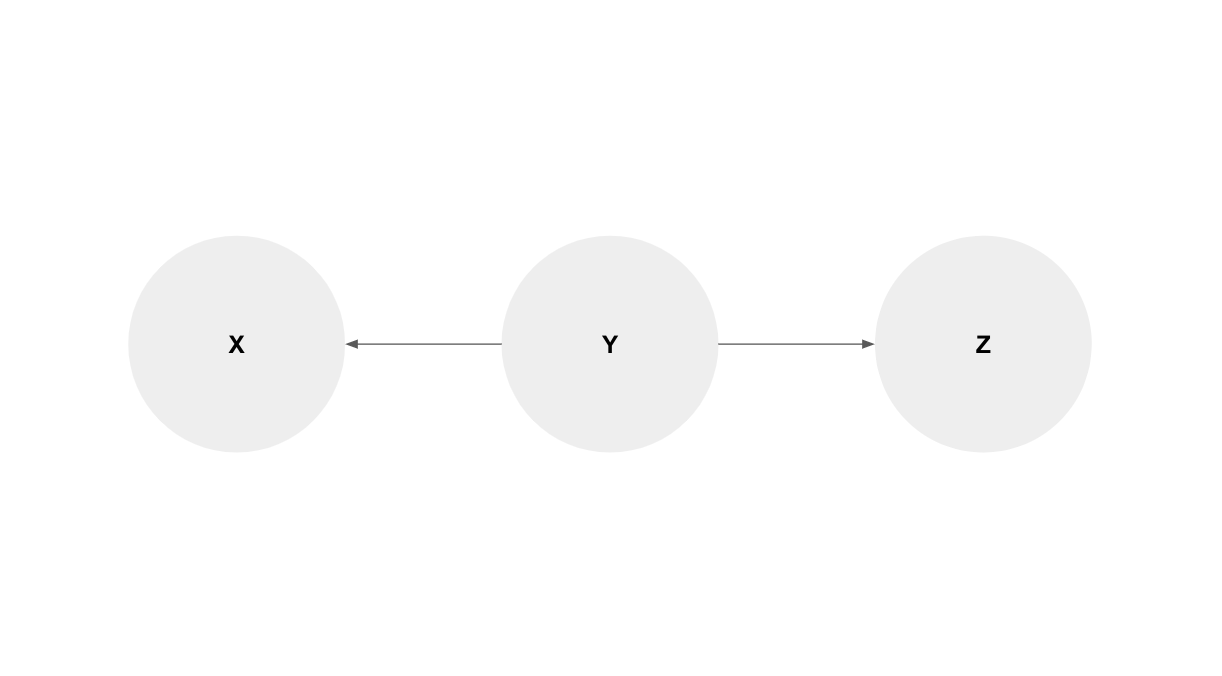
3.1.2 Confounders
“Y induce una asociación no causal (es decir, una correlación) en X y Z”. Interactuar con Y podría afectar esta asociación que podemos percibir entre X e Y. Piénsalo así: podemos ver en una gráfica que cuando crece X crece Z, pero eso no significa que uno cause otro o que aumentar X genere aumentos en Z. Es la expresión gráfica de la manida frase “correlación no implica causalidad”.
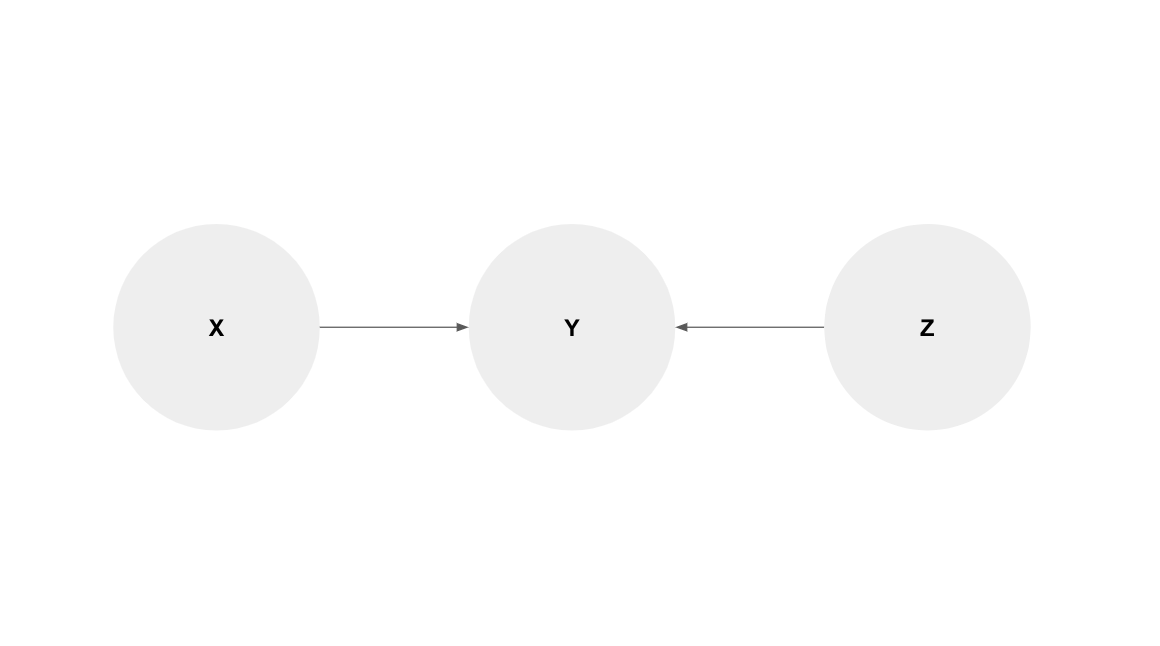
3.1.3 Colliders
“Y no induce una relación en X y Z”. Algo divertido sobre este efecto es el Collider Bias que abre la puerta a falsas asociaciones que a menudo hacemos sobre los fenómenos que nos rodean (en futuras ediciones profundizaremos en ello).
Un ejemplo de este sesgo: en algunos estudios se ha observado que la asistencia a clase puede reducir la probabilidad de obtener buenas notas. Sin embargo, esto puede ser un collider bias, ya que la asistencia a clase y las notas pueden influir en la probabilidad de ser encuestado (o de completar el estudio). Al restringir el análisis a los encuestados, se puede crear una asociación falsa entre asistencia y notas.
3.2 Métricas
Dentro del ámbito del análisis causal hay una serie de métricas que debes conocer para futuras ediciones ya que utilizaremos este vocabulario a menudo. No te preocupes: en siguientes ediciones te redigiré a este apartado para refrescar estas cuestiones.
Las métricas más comunes serían:
ATE (Average Treatment Effect): El efecto causal promedio que un tratamiento tiene sobre el resultado en toda la población. Es la diferencia en los resultados si todos los usuarios fueran tratados versus si nadie lo fuera.
Es decir, es el efecto causal global que se estimaría si toda la población estuviera expuesta al tratamiento (o no) respectivamente.
ATT (Average Treatment Effect on the Treated): El efecto causal promedio del tratamiento específicamente en el subgrupo de usuarios que sí recibieron la intervención. Compara sus resultados observados con lo que les habría sucedido sin tratamiento o intervención.
Es decir, es el efecto promedio en aquellos que SÍ han formado parte del grupo con tratamiento.
GATE (Group Average Treatment Effects): consiste en el efecto promedio del tratamiento de un subgrupo.
CATE (Conditional Average Treatment Effect): El efecto causal promedio del tratamiento para usuarios que comparten un conjunto específico de variables o covariables predefinidas. Permite analizar la heterogeneidad del efecto.
APO (Average Potential Outcome): El valor esperado del resultado (Y) para un nivel de tratamiento específico (D).
Es decir, permite estimar el resultado promedio si todos los individuos hubieran recibido un tratamiento particular o no.
3.3 Covariables
Las covariables son un elemento troncal que no solamente son relevantes en temas de análisis causal, también en métodos como CUPED y de reducción de varianza se utilizan este tipo de variables.
Las covariables son variables que pueden influir tanto en el resultado que nos interesa (Y) como en la asignación del tratamiento (D). En el análisis causal es clave para controlar el confounding, que ocurre cuando una variable afecta tanto la probabilidad de recibir el tratamiento como el resultado, creando una asociación no causal entre el tratamiento y el resultado observado.
En un análisis como los que debemos enfrentarnos a menudo en análisis causal, donde la asignación del cambio/tratamiento no es aleatoria (como sí sucede en un test AB normal de negocio digital), las covariables son fundamentales para intentar replicar las condiciones de un experimento aleatorio.
Si se controlan todas las variables de confusión, se asume que el tratamiento es "tan bueno como asignado aleatoriamente" condicionalmente a esas covariables, lo que permite estimar el efecto causal con mayor rigor.
Importante: Solo se deben considerar aquellas covaribles que son pre-tratamiento (es decir, no afectadas por el tratamiento en sí y que son previas, a menudo, al Día D). De hecho, la inclusión de "malos controles" o "colliders" (variables que son efectos comunes de otras variables) puede introducir sesgos, incluso si parecen estar correlacionadas con el resultado o el tratamiento.
¿Por qué nos interesa conocer todo esto? Porque a continuación adjunto una calculadora de diferencia en diferencias, un clásico dentro del análisis causal que forma parte del universo de las técnicas cuasi-experimentales y que representa una buena alternativa cuando no podemos usar Tests AB.
4. Diff-in-diff calculator
Pero… ¿qué es diferencia en diferencias? es un método utilizado para evaluar el efecto de una intervención comparando los cambios en los resultados entre un grupo tratado y un grupo de control. Sé lo que estás pensando: “¿pero esto no es como un test AB?”
Pues no, porque un test AB generalmente implica la aleatorización de la asignación del tratamiento en un único punto en el tiempo (una serie de semanas, habitualmente), mientras que en diff-in-diff se enfoca en el cambio en el tiempo de los resultados para el grupo que ha recibido el tratamiento o intervención comparando con el cambio a lo largo del tiempo para el grupo de control.
Un ejemplo simple: queremos evaluar el impacto de una campaña de email marketing en las ventas. Se seleccionan dos ciudades diferentes (Zaragoza y Pamplona, que comparten en nuestros negocios varios patrones comunes) y en una se implementa la nueva campaña (tratamiento) y en la otra se mantiene la antigua (grupo de control).
Se comparan las ventas antes y después de la implementación en ambas ciudades. La diferencia en el cambio de ventas entre la ciudad tratada y la de control revelaría el efecto causal de la nueva campaña.
¿Cómo funciona la calculadora?
Aquí tienes la calculadora de diferencia en diferencias. Esta es una calculadora un poco avanzada y no descarto hacer otra un poco más simple y accesible para aquellos más noveles en este campo. Lo estudiaré :D
¿Cómo funciona? Esta calculadora implementa un análisis de Diferencias en Diferencias utilizando DoubleML. Mediante una carga de CSV (con un formato determinado y necesario) permite calcular el efecto de una intervención de manera causal, proporcionando tanto la estimación puntual como un intervalo de confianza para una interpretación básica.
Tras la carga de datos (es decir, del CSV), se calcula la diferencia en la variable de resultado (Y) entre el período post-intervención y el pre-intervención para cada unidad y selecciona las covariables (X) del período base. Las covariables no son obligatorias.
Finalmente, se estima diff-in-diff con DoubleMLDID. La calculadora se enfoca en el "Average Treatment effect on the Treated" (ATT) e incluye un diagnóstico para evaluar supuestos como el balance de covariables y el solapamiento de propensiones.
5. Recursos de verano
Espero haberte generado ganas de aprender más y más de análisis causal. Con esta edición solamente quería dejar una serie de ideas clave encima de la mesa:
El análisis causal va un paso más allá que el ML tradicional en ciertas cuestiones.
ML funciona con asociaciones y no establece causas. Responder al por qué de cualquier cosa requiere de un profundo conocimiento sobre análisis causal.
El análisis causal es una solución muy válida en escenarios donde no podemos aplicar Tests AB, aunque ciertamente es una alternativa muy técnica y no accesible para todas las organizaciones y perfiles.
El análisis causal consiste en entender las relaciones, comprender cómo funcionan y abrazar una nueva manera de mirar el mundo.
En siguientes ediciones entraremos en cuestiones más técnicas y, de hecho, será la dirección estratégica de contenido de los siguientes meses de Leanalytics. Hasta entonces, ahí tenéis la calculadora y aquí un listado de libros sobre análisis causal que pueden ser una buena lectura. Están puestos en orden recomendada de lectura de menos complejo a más:
The Book Of Why - Judea Pearl
Causal Inference in Python - Mateus Facure
Causal Inference for data science - Aleix Ruiz de Villa
Inferencia y descubrimiento causal en Python - Aleksander Molak
Causal AI - Robert Osazuwa
¡Feliz verano!